I have been on a new project at work for about 3 months.
I am writing an application to read a data file and then transform it to another format but before we accomplish that, I have to learn the data format and what it all means.
For the past month and a half, I have been reading the specification and writing a program that will read the data, grab the header information, and put the result into an XML file. That part is now done.
All the data to be read in from the original file is in binary format and that is what I have been dealing with. I have not worked with binary data in over 35 years. I know how it is worked with but everything I learned back in college is still valid in theory but the actual tools to use have changed and that is what I am working to learn.
Let's review shall we -
Binary format is data that is either 0 or 1. This is also known as a base 2 numbering system.
[FYI, the numbering system we use in our every day life is base 10]
A BYTE is composed of 8 bits
00000001 = 1
00000010 = 2
00000011 = 3
etc.
There is such as thing as a nibble which is 4 Bits
And there are 2 nibbles in a Byte
A "word" is n number of bytes, but n depends on the type of computer system you are working on.
So way back when we got our first PC's that were 16-bit, that implied there were 2 Bytes in a word; in a 32 bit system, there were 4 Bytes in a word; and of course now that most of us are on 64 bit systems, we have 8 bytes in a word.
And when dealing with binary data; YES, you can Byte off more than you can chew (in a nibble) - ha ha.
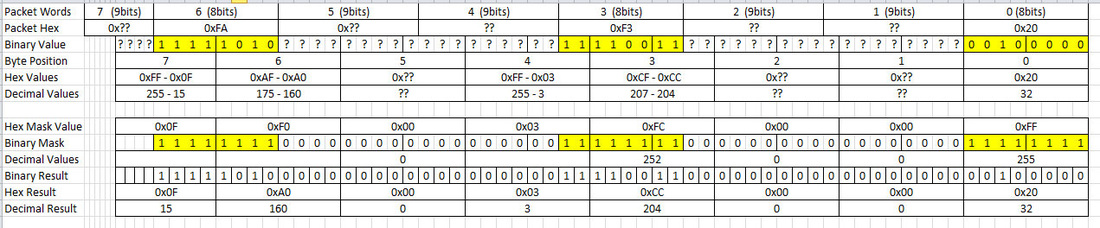
Well my data file is made up of packets of 2 Byte words so before I can even start to read the data, I have to first swap the byte positions such that the byte in position 0 goes to position 1 and what was in position 1 goes to position zero this is because the system writing the data is slightly different than the system that reads it on the computer I use.
After that I have to look for 3 Bytes (to be known from now on as the magical series).
The values which are: 0xFA, 0F3, and 0x20.
That is hexidecimal, which is base 16 which is counted as 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, A (in lieu of 10), B, C, D, E, and F (15 in decimal). So in normal speak I am looking for 250, 243, and 32 decimal values.
BUT get this, I can't just search for them across all the bytes; that would be way to easy. It turns out that the system that writes this data uses an odd system of bytes that are 8-9-9-8-9-9-8 bits but with a 8 bit writing to the file. SO this magical series of data that I have to look for is split across normal 8 bit Bytes but is contained in the weird series.
How does one find those values.... well that is what bit masking for and that alone is a whole blog post on it's own. Lets just say, it is like subtraction to find how many 2 you can actually see in the number 12 or 2,523 and what positions they are in. Bit Masking allows you to see if the 2 is in the first (12) or last position (2,523).
This image shows how I determined what the bit mask should be.
I am writing an application to read a data file and then transform it to another format but before we accomplish that, I have to learn the data format and what it all means.
For the past month and a half, I have been reading the specification and writing a program that will read the data, grab the header information, and put the result into an XML file. That part is now done.
All the data to be read in from the original file is in binary format and that is what I have been dealing with. I have not worked with binary data in over 35 years. I know how it is worked with but everything I learned back in college is still valid in theory but the actual tools to use have changed and that is what I am working to learn.
Let's review shall we -
Binary format is data that is either 0 or 1. This is also known as a base 2 numbering system.
[FYI, the numbering system we use in our every day life is base 10]
A BYTE is composed of 8 bits
00000001 = 1
00000010 = 2
00000011 = 3
etc.
There is such as thing as a nibble which is 4 Bits
And there are 2 nibbles in a Byte
A "word" is n number of bytes, but n depends on the type of computer system you are working on.
So way back when we got our first PC's that were 16-bit, that implied there were 2 Bytes in a word; in a 32 bit system, there were 4 Bytes in a word; and of course now that most of us are on 64 bit systems, we have 8 bytes in a word.
And when dealing with binary data; YES, you can Byte off more than you can chew (in a nibble) - ha ha.
Well my data file is made up of packets of 2 Byte words so before I can even start to read the data, I have to first swap the byte positions such that the byte in position 0 goes to position 1 and what was in position 1 goes to position zero this is because the system writing the data is slightly different than the system that reads it on the computer I use.
After that I have to look for 3 Bytes (to be known from now on as the magical series).
The values which are: 0xFA, 0F3, and 0x20.
That is hexidecimal, which is base 16 which is counted as 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, A (in lieu of 10), B, C, D, E, and F (15 in decimal). So in normal speak I am looking for 250, 243, and 32 decimal values.
BUT get this, I can't just search for them across all the bytes; that would be way to easy. It turns out that the system that writes this data uses an odd system of bytes that are 8-9-9-8-9-9-8 bits but with a 8 bit writing to the file. SO this magical series of data that I have to look for is split across normal 8 bit Bytes but is contained in the weird series.
How does one find those values.... well that is what bit masking for and that alone is a whole blog post on it's own. Lets just say, it is like subtraction to find how many 2 you can actually see in the number 12 or 2,523 and what positions they are in. Bit Masking allows you to see if the 2 is in the first (12) or last position (2,523).
This image shows how I determined what the bit mask should be.
Once I find a magical series, I have to break up that section of the packet of data into 2,000 byte lists and then find the next magical series.
But wait, there is one more twist. Occasionally the system that writes the data can toss out an extra bit or 2, or 3, and if this happens, all the rest of the bits are shoved off their position, I have to shift all the data x number of times (0-7 for a total of 8) and search for the magical series, again. Once the series is found, I can pull that data out and start searching again.
After 10 days of working on this bit of code (ha, ha a pun!) I have been able to process one channel (of 6) in one file. It is a big accomplishment as I can now move on to the next part which is to read a clock and assign a running time value to each piece of data.
Here are the numbers of what I was working in case you wanted to know:
But wait, there is one more twist. Occasionally the system that writes the data can toss out an extra bit or 2, or 3, and if this happens, all the rest of the bits are shoved off their position, I have to shift all the data x number of times (0-7 for a total of 8) and search for the magical series, again. Once the series is found, I can pull that data out and start searching again.
After 10 days of working on this bit of code (ha, ha a pun!) I have been able to process one channel (of 6) in one file. It is a big accomplishment as I can now move on to the next part which is to read a clock and assign a running time value to each piece of data.
Here are the numbers of what I was working in case you wanted to know:
- 9,378 packets of data in the file.
- With an average of 8,182 bytes per packet
- Total: 76,730,796 bytes to be searched or 613,846,368 bits.
 RSS Feed
RSS Feed